Red Hat Inc. today said it is contributing its Storage Hadoop plug-in to the Apache Hadoop open community as part of its big data strategy focused on offering enterprise customers infrastructures and platforms for open hybrid cloud environments.
Red Hat Storage Hadoop already provides compatibility with Apache Hadoop, one of the leading frameworks in the area. However, Ranga Rangachari, VP and general manager of Red Hat’s storage business unit, believes opening up its product to the community will transform Storage Hadoop into a more robust fully-supported, Hadoop-compatible file system for big data environments.
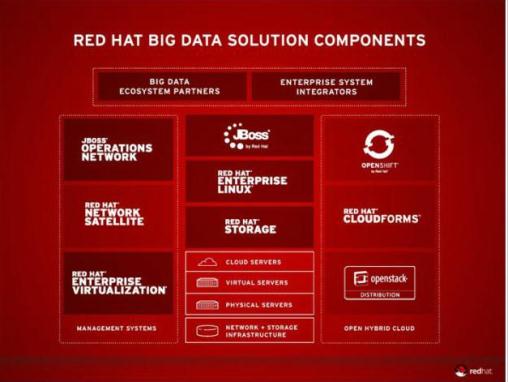
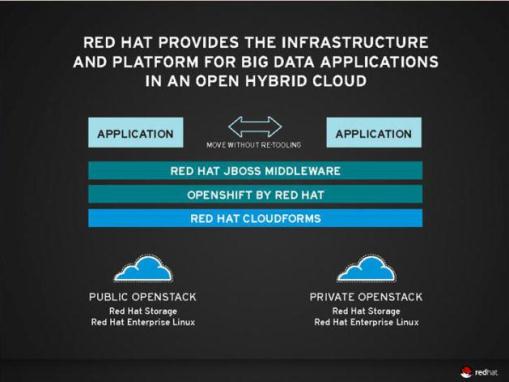
He also outlined Red Hat’s big data strategy which focuses on providing enterprise customers with infrastructure and application offerings ideally suited for open hybrid cloud environments. Red Hat is also developing network of ecosystem and enterprise integrator partners to delivery its dig data products to enterprise customers.
The big data solutions market is expected to grow from $6 billion in 2011 to more than $23.8 billion by 2016, according to Ashish Nadkarni, research director for storage systems at analyst firm IDC. He said Red Hat is poised to excel in the market because of its large inventory of offerings.
Hold onto you big data experts
Hortonworks unwraps a Hadoop sandbox
Wandisco’s mission critical-ready Hadoop
“Red Hat is one of the very few infrastructure providers that can deliver a comprehensive big data solution because of the breath of it infrastructure solutions and application platforms for on-premise or cloud delivery models,” said Nadkarni.
Red Hat is focusing on the open cloud community because this is where much of the big data development is going on, according to Rangachari.
“Many enterprise organizations use public cloud infrastructures such as Amazon Web Services for the development, proof-of-concept and pre-production phases of their big data projects,” he explained. “Once the workload is ready for production, they are moved to the private clouds to scale up the analytics with the larger data set.”
An open hybrid cloud environment enables users to transfer workloads from the public cloud to their private cloud environment without the need to re-tool or rewrite applications, he said.
Among the open cloud projects Red Hat is involved with are OpenStack and OpenShift Origin.